HashMap源码分析
条评论HashMap解析
基本用法
分析HashMap源码前,先看看怎么使用。
Map接口
首先看一下Map接口,Map接口里面定义了常用的方法。
public interface Map<K,V> { |
Map遍历
方法一,我认为最正统的写法
for(Map.Entry<String, Object> entry : map.entrySet()) { |
方法二,意思和上面的方法是一样的,看上去绕一些
Iterator it = map.entrySet().iterator(); |
方法三,先拿到key,再通过get()方法读取value,绕了一圈
for(String key : map.keySet()) { |
方法四,只能获取value,得不到key
for(Object value : map.values()) { |
源码分析
基于JDK1.8的源码进行分析。
数据结构
先上源码
package java.util; |
table:数组,保存数据;
threshold:阈值,当数组中的数据达到这个值以后,对数组进行扩容;
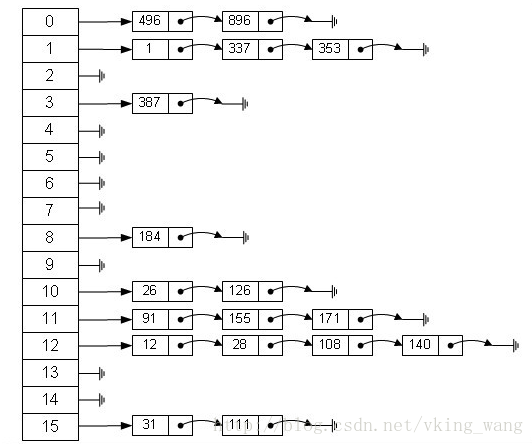
HashMap采用了链地址法来解决冲突问题,简单说,就是数组加链表的结合。在每个数组元素上都一个链表结构,当数据被Hash后,得到数组下标,把数据放在对应下标元素的链表上。
如上图所示,HashMap的基本存储结构是一个数组,根据key的hash值取模可以定位到数组的某一个元素,如果有多个key定位到同一个元素,通过链表连接(p1->next=p2)。读取数据时先根据key的hash值定位到元素,然后再遍历链表查找。如果分布不均匀导致某一个链表很长,就会降低效率。或者说,HashMap的容量间接决定了它的效率:当容量大时,每个key容易落到不同的数组位置上,一次就能读取到;当容量小时,多个key容易发生哈希碰撞,就需要遍历链表,效率自然就降低了。当然,大容量就占用了空间,还是典型的空间换时间。
static class Node<K,V> implements Map.Entry<K,V> { |
Node是真实存储键值对的数据结构:Node是HashMap的内部类,实现了Map.Entry接口,其中hash是key的原始哈希值,当扩容时需要用它重新计算数组下标位置,next指向下一个元素,默认为null,也就是说Node可以组成一个链表。
PUT流程
先看一下我总结的PUT操作流程,再看源码
GET操作流程
PUT源码
第一步,计算哈希值
public V put(K key, V value) { |
首先需要计算key的哈希值
- 调用hashCode()方法获取对象的int型哈希值;
>>> 16意思是无符号右移16位;^意思是异或操作,两位相同为0,不同为1(异或可以实现两数交换);- 高16位与0做异或,高位值不变;低16位与高16位做异或,混合高16位和低16位信息(称为扰动);
为什么要异或(或者为什么要扰动)?
- 我们知道hashCode()方法的返回值是int,范围是很大的,如果直接以这个返回值作为数组下标显然内存是不够用的,所以会采用类似取模的办法;
- 我们知道默认的数组大小是16,那么就是对16取模,相当于hashCode()返回值中只有最后4位起了作用,其他位都没有起到作用;即使int数比较分散,但是最后四位可能碰撞严重;换句话说,精心设计了哈希算法,计算出了分散的32位整数,但实际上只有最后4位起作用,效果可能还不好;
- 所以在JDK1.7中是这么做的,进行了多次扰动;(让高位与最后四位进行异或运算)
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
- JDK1.8认为四次扰动不必要,一次就够了,所以拿高16位与低16位进行异或计算;
- 我理解:如果数组大小为16,那么实际上是[0,4)和[16,20)位上的值决定了数组下标位置,其他位的计算是没有用的;当然,数组大小是可以扩容的,如果扩容到64,那么起作用的就是[0,6)和[16,22)位了。

上图充分说明了哈希和取模的过程。
如果容量选择31这样的质数,hash冲突就会小很多,但是取模计算和扩容就复杂了。HashMap才用16这样的非质数容量,必然导致冲突比31这样的质数多,中庸之道就是通过异或运算进行扰动综合。
第二步,取模
if ((p = tab[i = (n - 1) & hash]) == null) { |
i = (n - 1) & hash,假设n=16,那么&15就相当于&00001111,也就是保留hash的后四位的意思。
p=tab[i]就是根据key的hash值最终计算出来数组下标位置。
如果这个位置上的元素是空的,直接创建Node对象放到这里即可。
当n为2的x次方时,& (n-1)操作就起到了取模的作用,这就是为什么HashMap的容量总是2的x次方的原因。如果不是,那么%取模操作效率是很低的。
第三步,元素链表
if ((p = tab[i = (n - 1) & hash]) == null) { |
定位到数组位置后,遍历链表查找key是否存在,如果key存在直接返回value,不存在把新元素加入到链表末尾。
如果key存在,返回值一定是旧的value,至于是否使用新value替换旧value可以设置,默认是替换的。
put()方法是有返回值的,如果返回null不是说put()操作失败了,说明key不存在;如果返回值不为空,说明key存在,没有写入新数据,直接返回了存在的value。
key可以是null的,定位到数组0位置,但key是唯一的,所以只能有一个null的key。
比较key的时候是根据hash值进行比较的,所以使用String做key感觉比使用Object做key更放心一些。
第四步,扩容
// 简化代码 |
扩容优化
这部分代码是JDK1.8优化过的,需要解释一下。
Map<String, Integer> map = new HashMap(4); |
我们通过上面的实际例子来说明。为了简单,初始化容量为4,默认因子0.75,阈值为3。当put(“M”)时容量超过阈值,启动扩容操作。
扩容从4增加到8,我们看一下数组下标计算的变化:
hash(A)=01000001, hash(E)=01000101, hash(I)=01001001, hash(M)=01001101
容量为4的情况,截取最后两位,AEIM的最后两位都是01,对应的数组
01000001&0011=01, 01000101&0011=01, 01001001&0011=01, 01001101&0011=01 |
容量为8的情况,截取最后三位,AI的最后三位是001,EM的最后三位是101
01000001&0111=001, 01000101&0111=101, 01001001&0111=001, 01001101&0111=101 |
以上,可以看出:扩容以后,由于只是多截取了一位,所以数组下标或者不变,或者增加4(旧容量)。
因此,扩容时就不需要重新计算链表中每一个元素的新位置,要么不变,要么增加旧容量,所以才有了上面的算法:设立两个指针,loHead指向位置不变的,hiHead指向增加4的。了解了原理以后,我们再来看代码。
if ((e.hash & oldCap) == 0) |
注意,oldCap第一位是1,其他位都是0,所以& oldCap相当于判断hash值中新增加的哪一位的值。例如:继续上面的例子oldCap=100,hash(A)=01000001,01000001&100=0,其实就是在判断hash(A)的倒数第三位的值。我们知道原来只截取后两位,倒数第三位就新增的截取位。如果这一位等于0,数组下标就不变,如果这一位等于1,数组下标就加4。
所以,当(e.hash & oldCap) == 0时,将元素添加到loHead链表中,== 1时,将元素添加到hiHead链表中。
这样,遍历完旧数据后,就根据倒数第三位的值把就数据分为两份:loHead和hiHead,最后把它们放到数组中。
newTab[j] = loHead; |
红黑树
注意到put()代码里面有对TreeNode的特殊处理,这是JDK1.8新增加的红黑树。当链表很长时,遍历链表必然降低效率,所以当链表中元素个数超过8个时,不再使用链表,而改为使用红黑树存储,这样在get()时可以提高效率。
死循环
HashMap是线程不安全的,下面来具体分析一下多线程put()操作引起的get()方法死循环问题。
这个问题也可以描述成HashMap引发的CPU 100%问题,查看堆栈程序都Hang在HashMap.get()这个方法上,因为get()出现死循环,所以一直占用CPU。
首先,死循环的原因一定是链表出了问题,出现了循环链表。如果多线程并发put()操作出了问题,导致出现了循环列表,那么当get()查询到这个链表时,就会进入死循环出不来。
原理清楚了,下面看看具体的实例。
注意,例子是基于JDK1.7的,因为JDK1.7及以下才有这个问题。
void resize(int newCapacity) { |
JDK1.8保持了链表的顺序不变,所以不会出现循环链表的情况了,也就不会出现死循环了。虽然不会出现死循环了,但是还有可能出现其他问题,所以仍然不是线程安全的,在多线程环境下不建议使用。
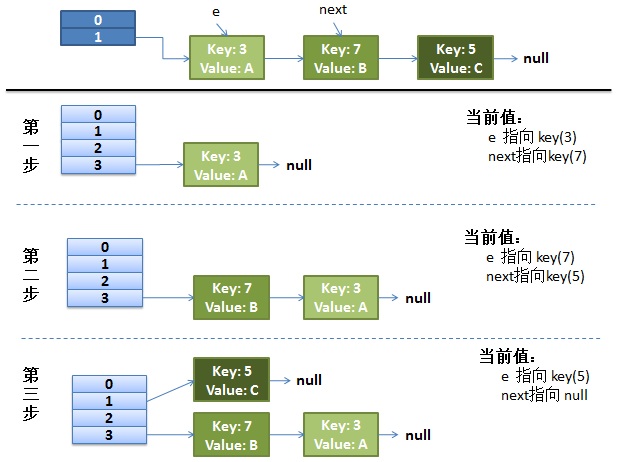
首先来看单线程的情况:
旧数据容量2,key的哈希值是3、7、5,都存储在table[1],新数据容量4,table[1]=5,table[3]=3、7;
数据迁移算法:遍历全部旧数据,将其从旧链表中摘下,插入到新链表的最前面。
接下来考虑多线程的情况,假设两个线程A和B,A线程执行到next = e.next; 时被挂起,B线程一直执行完成,那么当前状态如下:粉色表示线程A、天蓝色表示线程B。
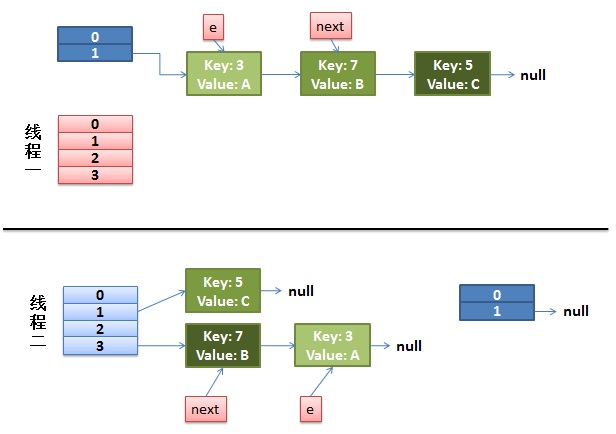
接下来线程A继续执行,当前e=3,next=7。将3插入到table[3]开头,然后,e=next=7。
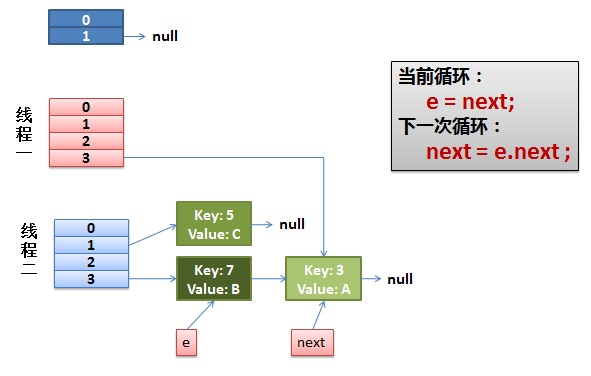
下一个循环,e=7,next=3,将7插入到table[3]开头,然后e=next=3。
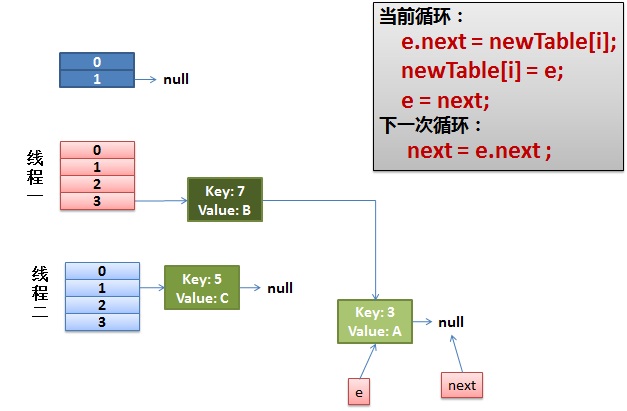
下一个循环,e=3,next=null,将3插入到table[3]开头,e=next=null。循环结束,最后的结果如下,形成了循环链表。
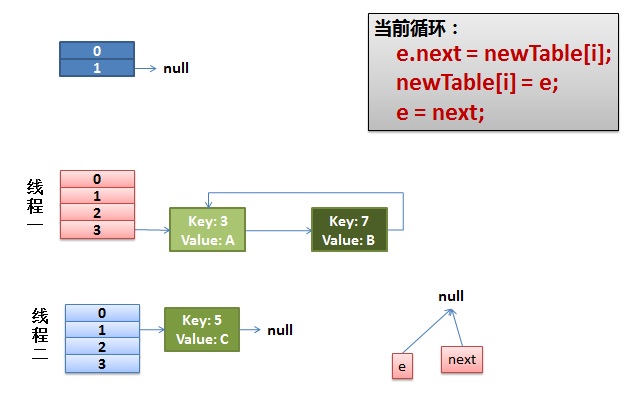
此时,如果线程A调用get(11)就会进入无限循环,问题重现。
Debug
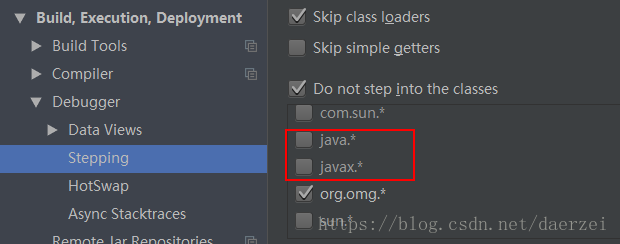
默认debug时是不能调试JDK源码的,具体体现就是单步执行和加断点失败,为了调试JDK源码需要修改配置:
Setting –> Build,Execution,Deployment –> Debugger –> Stepping
把Do not step into the classes中的java.* 和javax.* 取消勾选