分布式ID生成器
条评论分布式ID
在分布式情况下,尤其是分库分表情况下,如何生成表的主键是一个问题。
我们对于表的主键有两个要求:
- 一是唯一性,这是基础,也是最重要的要求,ID必须唯一;
- 二是顺序性,如果表ID是有序的,越来越大的,那么ID可以起到时间排序的作用;
在单库情况下,我们通常使用自增ID作为表的主键。
分库情况下,为保证ID的唯一,就需要手工设置各个库的auto_increment值以及步长,例如:我们把user表分到4个库中,db1从1开始,db2从2开始,db3从3开始,db4从4开始,步长都是4;这样,db1上生成的ID是[1,5,9,13,……],db2上生成的ID是[2,6,10,14,…..]。这样做问题不大,如果非要挑毛病,那么在一个db上ID是严格按照顺序创建的,但是跨db的ID顺序不能严格保证。例如,[5,6,7,8]因为在不同的db上,不一定是按照这个顺序创建的。
还有一种比较简单的办法就是直接使用UUID。UUID可以保证唯一性,并且不依赖于库。但是,UUID的问题是随机,没有顺序性,并且占用的存储空间比较大。
UUID的好处:
- 应用本地生成,保证唯一,数据库无感知。
UUID的坏处:
- 无法保证趋势递增;
- 32位字符串太长,占用存款空间大,占用索引存储空间大;
- B+树写操作时,过多的随机写操作,效率低(自增ID是顺序写);
- 作为主键查询效率没有bigint高;
- 高并发情况下,不能100%保证一定唯一。
Snowflake算法
Snowflake是Twitter生成64位自增ID的算法。
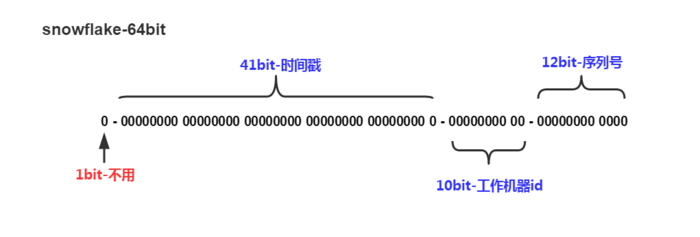
最高位不用,是0;接下来的41位是时间戳;接下来的10为是主机ID;最后12位是序列号。实际使用过程中,各组的位数可以根据实际情况进行调整。
SnowFlake的优势是本地生成,不依赖于其他任何第三方。我的理解:SnowFlake生成的自增ID有三部分组成:一、时间戳:为节省空间,可以不使用绝对时间,使用相对时间即可;例如:以2000年1月1日为时间基点,时间戳存储的是距离时间基点的毫秒数(实际上所谓绝对时间也是从1970年1月1日开始的)。二、进程标识:不同进程可能在相同时间生成ID,为了保证他们生成的ID不同,需要在ID中增加进程标志;进程标志可以是IP+Port,也可以自定义然后直接从配置文件中读取;三、进程内自增序号:解决同一个进程内并发的问题,使用AtomicInteger自增即可。
计算机元年就是1970年1月1日0时,加上时区因素,就是北京时间1970年1月1日8时。0毫秒就表示这个时间。
根据实际情况,我们也可以在上述三部分的基础上增加新的内容,例如业务类型。为保证ID具有顺序特性,通常时间戳都是放在最前面的;为了做分布式hash,通常自增序号都是放在最后面的;所以业务类型字段可以放在中间,进程标志的前后都可以。
回想一下,我们的order_bill_code其实也是类似的思路,业务类型+时间戳+自增序号(随机序号),殊途同归。