数据库水平拆分
条评论数据库拆分
垂直拆分
数据库垂直拆分就是要把表按模块划分到不同数据库中。微服务架构中每个服务拥有自己独立的数据库,就是典型的垂直拆分。通俗说,就是根据业务类型,把一个数据库中的多张表拆分到多个数据库中,这样不同数据库的数据量和压力不同,可以有针对性的进行优化。
水平拆分
垂直拆分只是把一张表拆分到另一个数据库实例中,并不会把一张表拆分为多张表。当单表的数据量增加到千万量级以上时,就需要拆表了,成为数据库水平拆分,也叫做数据库分片或者Sharding。
通常,我们认为MySQL数据库单表数据量在百万级,经过索引优化后查询效率是没有问题的。但是当数据量超过千万时,就需要考虑拆分了,如果超过五千万就肯定要拆表了。
数据库分片
数据库垂直拆分相对简单一些,分片就复杂多了,本文主要讨论数据库分片遇到的各种问题和解决方案。
一般我们根据表的主键和数据类型的不同来进行表的拆分,下面分别以用户表、帖子表和订单表为例,介绍如何进行拆分表拆分的三种方法。
用户表
用户表是典型的1对1例子,也就是说表的主键是user_id,1个用户只有1条记录。
背景
用户表保存用户姓名、手机号码、登录名、登录密码等基本信息,主键是user_id。在业务初期,单库单表就能满足需求,但随着数据量越来越大,需要对数据库进行水平切分,常见的方法有范围法和取模法。
方案
一、范围法:
将user_id设计为long型,根据user_id值的范围不同进行拆分。例如:1~1000万存储到db1中,1000万~2000万存储到db2中。
- 好处:
- 简单,读写时根据user_id可以迅速定位数据在哪个db上;
- 扩容简单,对历史数据无影响;每增加1000万用户,增加一个db即可。
坏处:
user_id必须是整数,且自增;
数据量不均匀,前面的db满了才会新增db,新增db数据量小;
访问量不均匀,一般新注册用户活跃度高,新db的负载比旧db负载高。
二、哈希法:
对user_id取模,除以总共的db个数,根据mod值分配db。如果user_id是字符串,可以先计算出哈希值,然后再根据哈希值取模。例如:5个数据库,user_id以1/6结尾的存储到db1中,以2/7结尾的存储到db2中,依次类推(是不是可以简称为限行算法?)。
- 好处:
- 简单,最多计算user_id的哈希值就可以确定db位置;
- 数据均匀,哈希值均匀分布可以保证数据均匀分布到各个db上;
- 访问量均匀,理由同上;
- 坏处:
- 扩容复杂,扩容以后可能引起数据迁移,如何平滑进行数据迁移是一个问题。
- 每次2倍扩容:概率上有一半的数据不用迁移。例如:开始2个数据库,1/3/5/7/9在db1上,2/4/6/8/10在db2上;扩容2倍到4个数据库,1/5/9还在db1上,2/6/10还在db2上,60%的数据不用迁移,需要做的是把3/7移动到db3上,4/8移动到db4上。
- 一致性哈希:一致性哈希算法可以保证增加和减少数据库数量时,尽量少的数据需要迁移。不过一致性哈希一般基数需要大一些效果才好,至少32或64起步吧,也就是说上来就开64个数据库,相当于单表数据量在10亿量级。所以,2倍扩容应该更常见。
问题
根据user_id分表以后带来的问题:
- 用户登录操作,需要根据登录名读取登录密码,现在有多张用户表,怎么办?都读取一遍?
- 同样,还有根据用户手机号码查询用户信息的需求?
- 此外,管理后台还有各种各样复杂、变态的查询需求,各种组合的,怎么办?
解决
先把查询需求分为前端需求和后台需求两种,使用不同的解决方案。
前端需求:通过登录名和手机号码查询用户,采用建立非主键属性到主键映射关系的方案。
后台需求:各种各样的复杂需求,采用前后端分离方案。
前端需求
根据手机号码查询
以根据user_phone查询user表为例。
建一张user_phone_id表,主键是user_phone,内容字段是user_id。查询时先通过user_phone查询user_phone_id表找到user_id,然后再根据user_id找到用户信息。user_phone_id表可以不分片。
考虑性能,也可以把user_phone_id表的信息缓存在redis中,如果redis缓存不命中,再查数据库。
user_phone和user_id的对应关系一旦建立很少改变,适合做缓存。
根据登录名查询
假设查询字段是user_login_name,当然可以使用和user_phone相同的方法。如果user_login_name字段不是用户输入的,是系统自动生成的,那么我们有更简便的方法。
缓存的出发点是空间换时间,预先把对应关系保存起来。另外一种思路就是设计一个函数f(x),保证f(user_login_name)=user_id,这样我们就不用查数据库了,直接结算就可以得到user_id。实际上我们不需要f(x)=user_id,因为我们不关心user_id具体是什么,我们只关系user_id在哪个db上,或者更专业点,在哪个数据库分片上。所以,我们只需要设计f(user_login_name)=db_sharding即可。这就简单了,我们创建用户记录时,根据user_id计算出db_sharding的值,然后放到user_login_name中就可以了。

如上图所示,最后三个字节保存的是user_id在那个db上(一共8个分片)。当根据登录名查询时,截取后三位就知道应该去哪个数据库查询了。
这种做法,需要考虑如果出现数据迁移怎么办,最好确定分片后就不变了。
后端需求
上面都是单条数据的查询,那批量查询怎么办?回想一下,前端用户只能查询自己的数据,只有运营后台才可以批量查询用户数据,后端需要采用不同的策略。
水平切分的目的是为了提高访问速度,后台查询条件复杂,对响应时间要求不高,所以不用分库,从前端通过MQ同步数据即可。MQ同步数据机制建立以后,也可以同步到Hive等其他存储结构中。
帖子中心
1对多。
订单中心
以order表为例
order_id
user_id
product_id
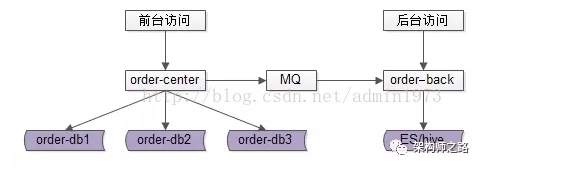
首先,区分前端访问和后台访问。前端访问指用户的访问,用户下单后需要查询订单,查询条件比较简单,一般只能查询自己的订单,但是响应速度要求要快。后台访问指运营人员对订单的查询,一般查询条件比较复杂,但实时性要求低一些。
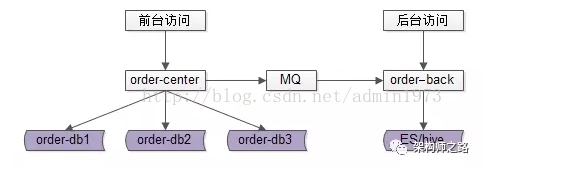
如图所示,order-center提供前端服务,order-center对应的数据库进行了水平切分;order-back提供后台服务,这里显示的存储方案是ES或者Hive,其实也可以是MySQL,总之后台服务的存储数据结构不依赖于前端,可以根据实际业务需求进行选择。如果选择了MySQL,后台存储可以选择不分库,因为后台需求往往逻辑比较复杂,但是对响应性要求不高。
前后端数据同步可以通过开源的中间件来实现,更多的时候像图中一样,通过MQ来同步。MQ异步同步意味着数据是有延迟的。MQ要保证数据送到的可靠性和幂等性。
不只是订单服务,后台可以把所有前端服务产生的数据都汇总到一个库中,可以是原始数据直接进入,也可以是经过order-back处理后的数据进入。(看上去有点像数据仓库了。)
接下来看,前端的数据库存储如何做水平拆分。
这里有一个前提,前端用户查询的都是自己的订单,不能查询别人的订单。这样,我们就可以根据user_id来分库。例如:如果分为4个库,那么最简单的办法对user_id % 4,来确定订单数据落在那个schema上面。实际操作中,我们是通过主键order_id来做水平切分的,所以要保证order_id和user_id的切分一致。所以在生成订单时,可以让order_id的最后两位和user_id 的最后两位一致,或者最简单order_id=timestamp+user_id,这样取模就肯定和user_id一致了。
https://mp.weixin.qq.com/s/PCzRAZa9n4aJwHOX-kAhtA
https://blog.csdn.net/admin1973/article/details/74923283